
What is DataOps and why is it so relevant to the financial services sector?
The sheer volume of data collected by financial services due to the nature of the industry, has led to the rapid growth of data storage and in turn, potential opportunities to outsmart competitors. The data collected and stored by financial institutions includes an extensive amount of customer data, financial transactions, website and app data and vendor intelligence. The finance cloud market size is estimated to grow to $29.47 billion by 2021, at an estimated CAGR of 24.4% since 2016. The main drivers for cloud adoption in financial firms consist of improved business agility, the need for better customer management and increased efficiency, whilst meeting stringent regulatory and data protection requirements.
Utilising leading-edge data and analytics capabilities can have a big impact on the financial services sector. Making data-driven business decisions as opposed to intuitive decision making is possible when data is effectively managed and can be seen in it’s entirety. For example, data analytics can enable banks to gain insight into their customers that can turn into strategic choices regarding new products and business models. Risk can be lowered for banks with more effective assessments and decisions based on risk profiles during credit applications, taking into account much more detail on the individual or business who is applying.
Financial services organisations need to be agile and innovative in their approach in order to keep up with the changing face of modern life. The amount of data that flows through different parts of these organisations is not necessarily being leveraged well due to legacy systems, silos, data governance issues, and for many, they simply don’t know where data lies. Consumers expect personalised interactions and information at their fingertips therefore customer segmentation and targeting has become a key strategy. A crucial way of mastering this capability with agility across the organisation is through operationalising data management to ensure a fast flow of valuable information across departments.
A method we’re going to talk about in this article is Data Operations (DataOps), which 75% of companies plan to invest in, according to a survey in 2018. DataOps in financial services is continuing to gain significant traction and is transforming the way data is managed and utilised in organisations.
What is DataOps?
The terms DataOps is widely recognised for being coined by Andy Palmer, in a blog post in 2015. He explained it as a natural evolution of DevOps, applied to data as a practice. He summarised it as
"a data management method that emphasises communication, collaboration, integration, automation and measurement of cooperation between data engineers, data scientists and other data professionals."
DevOps uses the Agile approach to software development, which aims to speed up the development life cycle whilst maintaining a high quality. It often encompasses the automation of integrating, testing and deploying code. 97 percent of organisations now say that they practice Agile development methods, to keep up with the demands of modern software and application development. When applied to data, this approach drives an efficient and flexible way of managing data and analytics, aiming to reduce the time taken to produce analytics that aid in garnering business insights.
DataOps has a human side to it, whereby collaboration and integration is key to success. It’s not tied to specific technologies, tools, languages or frameworks. The tools chosen should seek to improve collaboration, innovation, quality, security, access and useability. The DataOps team which includes data scientists and data engineers needs to be able to bring together different data types from multiple, disjointed sources and remodel it into a valuable resource for users across the business to utilise.
Data teams face multiple challenges in dealing with diverse technical and business teams across the business which often makes projects more complex. DataOps can help data teams and business users work together in a more collaborative and efficient way. It gives consumers of data in the business access to analytics tools so that they can gain their own insight into data first-hand. It automates parts of the analytics development lifecycle, speeding the cycle up.
Financial services organisations can find their own path to adopting DataOps, freeing data silos that have been created from large legacy systems that were not built for the fast pace of the modern business world.
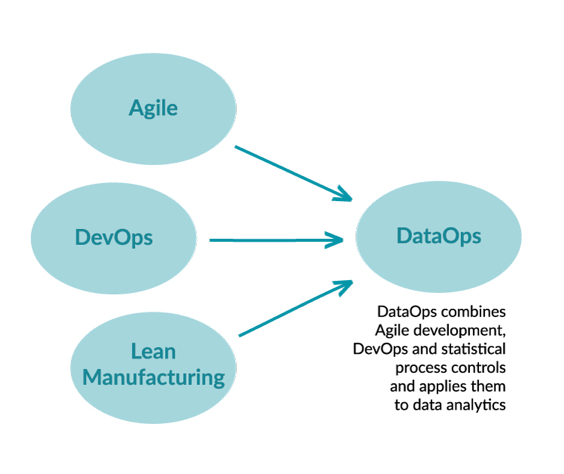
The principles of DataOps
The principles of DataOps are borrowed from the practice of DevOps, as well as Agile and Lean Manufacturing, and supports data teams and data users to work together more efficiently and effectively.
Agile development, the iterative project management methodology is utilised in settings where requirements can change often, which makes it highly relevant to data-first organisations. Data teams can use this methodology to drive quicker business decisions which is where the true value really lies. By reducing the time it takes to find the right data or by putting data science models into practice more quickly, performance and capability will inevitably be improved.
Data teams use the principles of DevOps to collaborate better and deploy faster. In practice, there would be no need to rely on IT to deploy data science models, data scientists would be able deploy their models themselves. Consumers of data within the business could have access to self-serve analytics, with less reliance on data teams to provide analytics on a frequent or ad-hoc basis.
DevOps is also applied to data teams and users within a business, by facilitating collaboration and feedback on data quality continuously. Specifically, in the financial services sector, the ability to carry out frequent quality checks is incredibly important to verify that data is being used how to should and is meeting the required standards for audits and regulatory requirements.
In DataOps, statistical process control (SPC) is a borrowed methodology from lean manufacturing that uses real-time indicators to monitor and control quality. If the set measures are not maintained, the process is not functioning as it should and can be flagged up within the team. By setting up a data quality process and defining what looks good, automated checks can be used to test the quality of data. Integrating tests into data pipelines allows quality control, which will come ahead of automating processes if the test succeeds.
A data pipeline can be thought of in the same way as a manufacturing production line, where data enters and exits continually, and quality and efficiency is key to the operation. The continuous data analytics pipeline is monitored, improved and automated where possible.
A concept of DataOps is "analytics is code" meaning that all parts of the process should be modular, automated and reusable. There are 18 principles in the DataOps manifesto which explain the approaches that have been borrowed or created for better data management practice. Another key principle is that data scientists and engineers should have safe, isolated data environments for experimenting and testing purposes that are disposable. This is made possible through the use of tools like automation and cloning, and enables faster deployments and minimised risks.
DataOps has a focus on people at all parts of the processes involved. It touches many people across the organisation, and for some businesses, the collaboration element may be a big change across departments where silos ordinarily exist. It provides easier access to data amongst stakeholders such as IT operations, data scientists and data engineers enabling many valuable use cases. The blend of people, processes and technology make up a successful implementation of DataOps. Simplicity is championed when looking for solutions in a DataOps environment, and it is the business strategy that is the starting point for the DataOps strategy so that data teams and the business are working towards its goals.
The benefits of DataOps in financial services organisations
The rate at which the finance sector has taken up new technologies has steadily increased over the years as competition has become fierce and large technology businesses and fintechs have entered the sphere, providing new value to consumers.
Collaboration and transparency
DataOps does not just include the data team, it includes many business stakeholders and requires a multidisciplinary approach to get the most from data. By setting out ways of working inspired by the DevOps, Agile and Lean methodologies, the roles within departments will be clearer. Data teams must consistently bring value to the business, respond to ad hoc demands and manage a number of processes related to operations. Transparent workflows make it possible for people within the business to understand the complexity of working with data and where a project is up to.
Setting up processes to enable self-service analytics for data scientists wishing to deploy their models themselves will benefit everyone and make collaboration simpler. The previous way of working meant that data scientists had to rely on IT or engineering for deploying their models, creating a dependency, slowing down their ability to perform analysis.
Increased speed
Naturally, implementing DataOps will bring about faster performance of data teams and efficiency for business users using analytics. The new focus on quick release cycles and refining iteratively means delivering early whilst meeting high quality standards. Within financial services, speed has historically been an issue as data pipelines are incredibly complex in the large institutions and data has been siloed, with risks requiring incredibly careful management when pushing changes to live, critical pipelines.
Creating virtual development environments makes it easier to test changes without having to worry about impacting users, speeding up the process and giving data teams time back to iterate and improve the pipeline. Delivering new analytics faster is made possible by approaching the end-to-end data lifecycle using the DataOps methodology. This in turn, enables organisations to become more intelligent and gain actionable insights into their customers, leading to the creation of new products and well-timed offers.
Automation is a promising way to address the issue of data engineers spending too much time on troubleshooting. Data engineers reported that they spend an average of 18% of their time troubleshooting, yet there are ways of using automation to clean up data and carry out other tasks typically called “grunt work”. This allows data engineers to spend more of their time on higher value tasks and for the business, it frees up resources, encouraging projects and operational work to be completed sooner.
Managing fraud, cybersecurity and compliance
AI and machine learning are the modern techniques of choice for the management of cybersecurity threats and fraud detection within the financial services sector. DataOps can directly impact and improve a company’s ability to utilise AI meaningfully. Fraud detection is a relevant use case for DataOps as many of the practices of it can decrease false positives by using data and logic testing to maintain a consistent performance and find errors in source data, before they’re able to impact results.
Compliance in the finance sector continues to evolve globally and requires the ability for organisations to be able to simply aggregate data and report on it across many areas of the business. With the improvement in transparency of how data moves within an organisation, DataOps in financial services guides better compliance with regulatory requirements and data protection laws. In the case of Know Your Customer (KYC) and Anti-Money Laundering (AML), proactive monitoring and a consistent, complete view of customers is required to meet regulations that ask for accurate and up-to-date information. By improving the quality of data through DataOps and implementing AI to recognise patterns in financial data, financial institutions can be alerted quicker o potential risks. The end result is improved productivity and confidence that data is accurate, whilst meeting compliance.
Increase the quality of data
Guaranteeing data quality, security and integrity is critical for analysts and others that rely on data to create visualisations and reports. The nature of DataOps provides a data governance framework that is set up for success with testing and rapid improvements through iterative processes. By automating data quality checks when data arrives, alerts can be set up so that if the quality hasn’t been met, it can be addressed at pace by the team.
Data quality checks are just as relevant for outputs and require a set of measures for what is being produced. It’s key to understand what the output needs to look like, and this is likely going to be known by people in multiple teams and should be collated. Agile, cross-functional teams are able to deliver data value more rapidly and effectively by staying aligned on the goals and measures for creating quality for the organisation.
Change with the business needs
Approaches to data management in the past have started with focusing on what data is available for use, which does not always align with the goals of the business. By starting with the strategic goals, it’s important to allow for the flexibility to take on new approaches that fit a specific challenge being faced. DataOps encourages this fluidity by following an iterative method that allows changes and new tools and techniques to be implemented in the cycle.
Data is messy and unpredictable, particularly in large institutions that have an array of data sources. By utilising DataOps, financial services organisations can optimise data management, impacting the business greatly with insights that drive decision making for success. Collaboration is at the heart of this methodology, placing importance on people and not just processes, so that data can flow smoothly between data managers and data users. In the constantly changing landscape that is finance and technology, the Dataops practice is one that allows businesses to adapt quickly and with confidence.
To learn more about implementing DataOps in financial services organisations book a free consultation.






